이전 글에서 카프카의 기본 개념을 정리하였으니, 지금부터는 실제 활용방법에 관하여 설명한다.
카프카 설정파일
카프카는 설치시 config파일에 옵션을 설정해줄 수 있다. 해당옵션은 중요한 사항이므로 필요한 옵션들은 알아두어야한다.
- config/server.properties
- broker.id: 브로커식별 id. (정수로 지정. 클러스터구성으로 브로커가 여러대있을때는 모두 달라야함)
- advertised.listeners: 다수의 클라이언트들(리스너)이 해당 브로커를 찾을 수 있도록 브로커의 ip:port를 입력.
- log.dirs: 브로커는 프로듀서로부터 메시지를 받고 파일로 저장해놓는다. 그 저장할 파일의 경로를 지정. 기본값이 /tmp/이므로 삭제되는 경우가 발생하기때문에 꼭 설정해주어야한다.
- zookeeper.connect: 브로커의 메타데이터를 저장하는 주키퍼의 호스트 정보. 동일한 주키퍼 클러스터의 여러 노드를 ', '로 구분한 문자열로 지정가능. 예를 들어, 'zookeeper01:2181, zookeeper02:2181'와 같이 지정. 또한 'zookeeper01:2181, zookeeper02:2181/my/path'처럼 주키퍼 내부의 저장 위치를 함께 설정할 수 있다.
- offsets.topic.replication.factor: 브로커에 토픽을 복제할 개수. 다만 기본값이 3이므로, 브로커가 3대미만이라면 에러발생. 브로커는 자기자신에게 복제본을 두지않기때문에 복제본을 둘 브로커가 없으면 에러. 카프카 1대라면 1로 작성해야함.
- log.segment.bytes: 메시지가 저장되는 파일의 크기 단위
- log.retention.ms: 닫힌 메시지를 얼마까지 보존될지를 지정. 닫힌 세그먼트를 처리
- auto.create.topics.enable: 자동으로 토픽이 생성여부 (디폴트 true)
- num.partitions: 자동생성된 토픽의 default partition 개수
- message.max.bytes: kafka broker에 쓰려는 메시지 최대 크기
원래 카프카가 실행되려면 주키퍼가 3개이상 떠있고.. 이런게있어야하는데 binary파일을 다운받으면 1대의 주키퍼만 키면 실행할수있다
카프카 실행파일
- 토픽생성 : ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic coffee-dto
- 토픽리스트 : ./kafka-topics.sh --list --zookeeper localhost:2181
- 토픽세부정보 : ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic coffee
- 토픽삭제 : ./kafka-topics.sh --delete --zookeeper localhost:2181 --topic coffee-dto(config = true설정하고, 주키퍼rmr삭제)
- 프로듀서 : ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
- 컨슈머 : ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic coffee --from-beginning
- 컨슈머그룹 : ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -group testgroup --from-beginning (컨슈머 오프셋확인,수정)
- 컨슈머그룹 리스트 : ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
- 컨슈머그룹 삭제 : ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group kafka-intro234
- 컨슈머그룹상태확인 : ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testgroup --describe
- 컨슈머그룹오프셋되돌리기 : ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testgroup --topic test --reset-offsets --to-earliest --execute
- --shift-by <Long> : 컨슈머 오프셋에서 + 또는 - 이동
- --to-offset <Long> : 컨슈머 오프셋을 지정
- --to-latest : 가장 최신(높은숫자) 오프셋으로 지정
- --to-earliest : 가장 이른(낮은 숫자) 오프셋으로 지정
- 컨슈머그룹특정파티션되돌리기 : ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testgroup --topic test:1 --reset-offsets --to-offset 3 --execute
- (1번파티션을 3번오프셋으로 돌려라)
카프카 실습
위의 실행 쉘로, cmd를 2개 띄워서 컨슈머 & 프로듀서를 각각 띄워본다. 토픽은 동일하고 파티션은 3개로 지정.
프로듀서에 데이터를 입력하고 컨슈머가 데이터를 잘 읽어들이는지 확인한다.
프로듀서로 토픽에 1234567 을 집어넣었을때 파티션에 이렇게 들어있다고 가정하면,
파티션 0 : 1 4
파티션 1 : 2 6 7 → 컨슈머에 1426735 이런식으로 순서가 보장이 되지않음 / 파티션이 1개면 순서를 반드시 보장
파티션 2 : 3 5
이상태에서 컨슈머그룹 쉘을 끄고, abcd를 추가적으로 넣고 컨슈머그룹쉘을 다시 켜면,
파티션 0 : 1 4 a b
파티션 1 : 2 6 7 d → 컨슈머에 abdc 이런식으로 오프셋 이후의 값만 출력됨.
컨슈머그룹은 파티션마다의 오프셋을 저장하고있다는뜻
파티션 2 : 3 5 c
컨슈머그룹없이 컨슈밍하면 가상의 컨슈머그룹이 생기고, 컨슈머그룹을 지정해주면 컨슈머그룹이 알아서 생성됨.


이런식으로 testgroup 이라는 컨슈머그룹은 파티션 3개로 구성되어있으며, 각 파티션이 어디까지 쓰여졌으며 또 어디까지 읽혔는지 확인가능하다. lag이 쌓인다는것은 그만큼 작업이 밀리고 있다는 뜻이다.
프로듀서(Producer)
- 카프카로 데이터(key, value)를 전송
- ProducerRecord 객체 생성
- Java Kafka-client 제공 (자바 이외는 https://cwiki.apache.org/confluence/display/KAFKA/Clients 참조)
옵션
필수옵션 - 반드시 입력
- bootstrap.servers: 카프카 클러스터에 연결하기 위한 브로커 목록
- key.serializer: 메시지 키 직렬화에 사용되는 클래스
- value.serializer: 메시지 값을 직렬화 하는데 사용되는 클래스
선택옵션 - default값 존재
- acks: 레코드 전송 신뢰도 조절(리플리카) 중요
- comression.type: snappy, gzip, lz4 중 하나로 압축하여 전송
- retries: 클러스터 장애에 대응하여 메시지 전송을 재시도하는 회수
- buffer.memory: 브로커에 전송될 메시지의 버퍼로 사용 될 메모리 양 → batch 한번에 전송한다
- batch.size: 여러 데이터를 함께 보내기 위한 레코드 크기
- linger.ms: 현재의 배치를 전송하기 전까지 기다리는 시간
- client.id: 어떤 클라이언트인지 구분하는 식별자
자바코드
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
for (int index = 0; index < 10; index++) {
String data = "This is record " + index;
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, data); // 토픽명, 값
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, Integer.toString(index), data); // 토픽명, 키, 값
ProducerRecord<String, String> record =
new ProducerRecord<>(TOPIC_NAME, PARTITION_NUMBER, Integer.toString(index), data); // 토픽명, 파티션, 키, 값 (파티션을 지정하기때문에 순서보장)
try {
producer.send(record);
System.out.println("Send to " + TOPIC_NAME + " | data : " + data);
Thread.sleep(1000);
} catch (Exception e) {
System.out.println(e);
}
}
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --property print.key=true --property key.separator="-"key도 value값과 같이 보여주되, -구분자로 값을 구분해서 같이 보여주라는 뜻. (from begining없으므로 켜논상태에서 거래를 쏴야함) 위의 예제에서는 이런값이나옴
0-This is record 0
1-This is record 1
2-This is record 2
null-This is record 3 ← 키를 안넣었는데 같이뽑겠다면 NULL값으로 나옴
레코드 key
메시지를 구분하는 구분자 역할.
- 동일키는, 디폴트파티션에의해 동일파티션에 적재된다. → 순서를 보장하므로 상태머신으로 사용가능
- 역할에 따른 컨슈머 할당 적용가능
- 레코드 값을 정의하는 구분자(키에 레코드값 해쉬값을 넣음으로써 중복처리 방지기능)
레코드 value
실질적으로 전달하고싶은 데이터
- String, ByteArray, int 등 보내는 타입은 제한이 없음
- CSV, JSON, Object 등 서비스의 특징에 맞게 사용 권장csv 사용시, 콤마기준으로 데이터 구분. 용량이득
- json 사용시, key/value 형태로써 확장성이 뛰어남.
Producer acks
- acks = 0 가장 속도는 빠르지만, 유실가능성 높음

프로듀서가 브로커와 소켓연결을 맺어 보낸 즉시 성공으로 간주.
브로커가 정상적으로 받아서 리더 파티션에 저장했는지 알 수 없음.
팔로워 파티션에도 저장됐는지 알수없음.
속도가 중요하기때문.
- acks = 1(디폴트) 속도는 보통, 유실가능성 있음
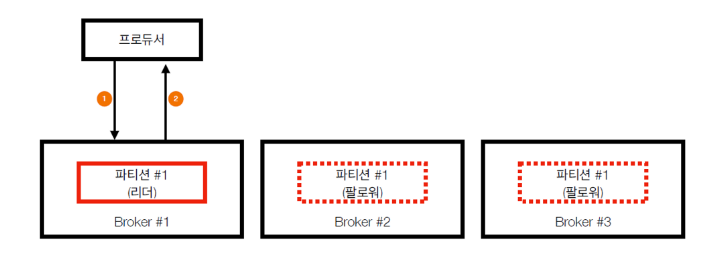
프로듀서가 보낸 메시지가 리더파티션에 정상 저장되었는지는 확인
팔로워파티션에 저장됐는지는 모름
즉, 리더 파티션에만 저장되고 ISR되기전에 해당 브로커가 죽으면 데이터 유실
ack=0에 비해 신뢰도는 높지만 유실가능성은 존재
- acks = all or -1 속도는 느리지만 유실가능성 없음

프로듀서가 보낸 메시지가 리더, 팔로워 파티션에 정상 저장되었는지 확인
리더 파티션의 데이터가 팔로워 파티션까지 복제될때까지 기다림(ISR 상태까지 기다린다는말)
복제가 완료되기까지 기다림으로 인해 속도는 느리지만, 유실가능성은 없음
컨슈머(Consumer)
- 데이터를 가져가는(폴링) 주체. 브로커가 보내는것이 아니라 컨슈머가 가져가는것
- commit을 통해서 읽은 consumer offset을 카프카에 기록
- Java Kafka-client 제공 (자바 이외는 https://cwiki.apache.org/confluence/display/KAFKA/Clients 참조)
- FileSytem, Hadoop, RDBMS, NoSql.. 등의 저장소에 데이터를 저장함
옵션
필수옵션 - 반드시 입력
- bootstrap.servers: 카프카 클러스터에 연결하기 위한 브로커 목록
- group.id: 컨슈머 그룹 id
- key.deserializer: 메시지 키 역직렬화에 사용되는 클래스
- value.deserializer: 메시지 값을 역직렬화 하는데 사용되는 클래스
선택옵션 - default값 존재
- enable.auto.commit: 자동 오프셋 커밋 여부 (true일 경우, 속도가 빠르며 commit관련 코드를 작성할필요가 없어서 편리하지만, 중복 & 유실이 발생할 수 있음)
- auto.commit.interval.ms: 자동 오프셋 커밋일 때 interval 시간
- auto.offset.reset: 신규 컨슈머그룹일 때 읽을 파티션의 오프셋 위치
- client.id: 클라이언트 식별값
- max.poll.records: poll() 메서드 호출로 반환되는 레코드의 최대 개수
- session.timeout.ms: 컨슈머가 브로커와 연결이 끊기는 시간
자바코드
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // 프로듀서와 반대로 역직렬화 필요
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); // 자동으로 커밋할건지 여부 (어디까지 읽었는지 기록, true 디폴트)
configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 60000); // 60초마다 자동커밋 <- 60초가 지나기전에 프로세스가 죽으면 이전시점부터 다시읽어들임
// 데이터가 중복처리될수있다는뜻이므로 (은행,카드사에서 사용금지)
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME)); // 해당 토픽명 구독 선언
while (true) {
// ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}consumer.subscribe(Arrays.asList("click_log")); // 1개 토픽만 구독
consumer.subscribe(Pattern.compile("dev.*")); // n개 토픽구독(정규식)
consumer.assign(Conllections.singleton(new TopicPartition("web_log", 1)));
// 특정토픽 파티션 구독 (key를 포함한 레코드를 컨슘할때, 특정파티션만 할당하고싶을때)
enable.auto.commit: true일 경우, 속도가 빠르며 commit관련 코드를 작성할필요가 없어서 편리하지만, 중복 & 유실이 발생할 수 있음
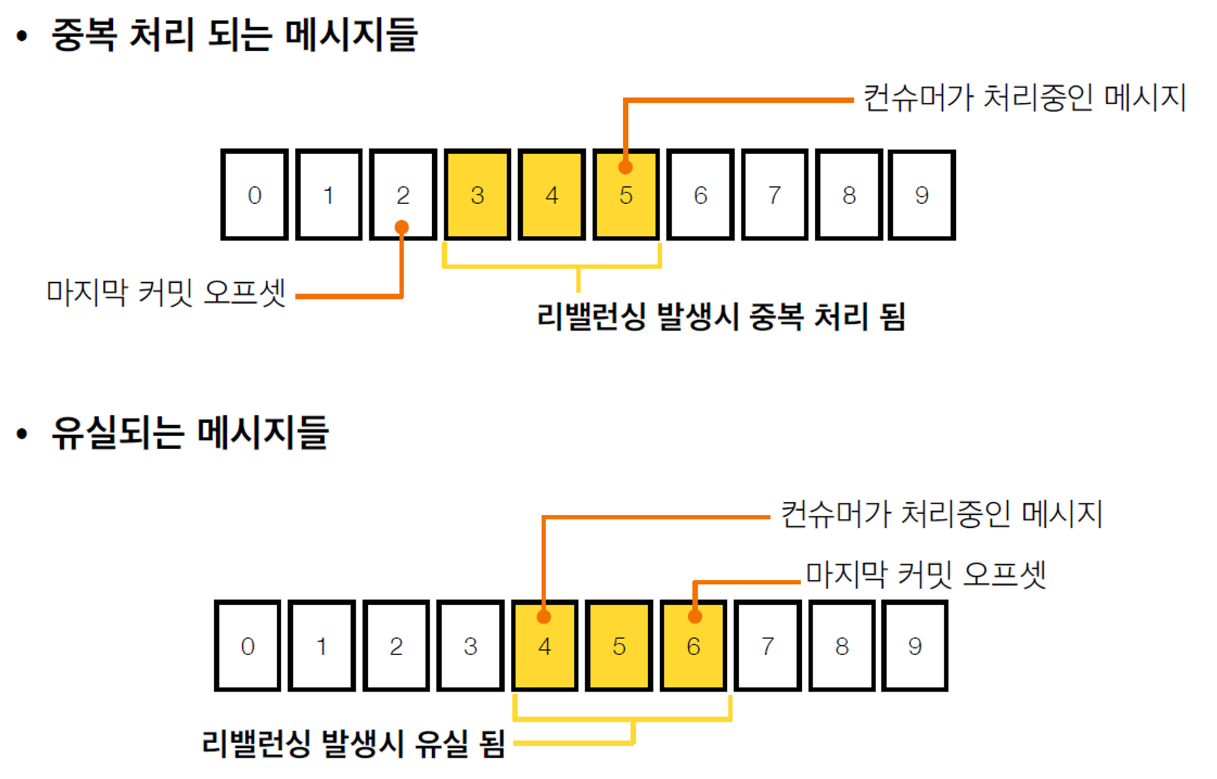
데이터 중복 & 유실을 막을 수 있는 방법
→ 오토커밋을 사용하지않는다. enable.auto.commit: false && commitSync(), commitAsync() 사용
- commitSync() : 동기 커밋
- consumerRecord 처리 순서를 보장함 (가장느림)
- poll() 메서드로 반환된 consumerRecord의 마지막 offset을 커밋
- Map<TopicPartition, OffsetAndMetadata>를 통해 오프셋지정커밋 가능
- commitAsync() : 비동기 커밋
- 동기커밋보다는 빠름
- 중복이 발생할수있음. 일시적인 통신문제로 이전 offset보다 이후 offset이 먼저 커밋될때
- consumerRecord 처리순서를 보장하지못함
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 오토커밋을 하지않음
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
consumer.commitSync(); // 커밋싱크
// record.offset();
}
}
리밸런스
컨슈머 그룹의 파티션 소유권이 변경될 때 일어나는 현상
- 리밸런스를 하는 동안 일시적으로 메시지를 가져올 수 없음
- 리밸런스 발생시 데이터 유실/중복 발생 가능성있음
- consumer.close() 호출 & consumer 세션이 끊어졌을대 리밸런스 진행
...
consumer.subscribe(Arrays.asList("test"), new RebalanceListener());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
static class RebalanceListener implements ConsumerRebalanceListener { // 로그를 남겨두던지의 행위가 가능
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Lost partitions.");
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Assigned partitions.");
}
}
wakeup
컨슈머를 정상적으로 종료시키기위해 wakeup()사용.
컨슈머가 한번 땡겨올때 101~200오프셋을 땡겨온다고 가정할때, 150번째를 진행하는도중 강제종료가 난다면, 커밋을 하기전에 에러가났으므로 다음번에 호출시에도 101~200을 가져온다. 이러한 경우는 101~150까지는 중복처리가 될 수 있음. 이럴때 중복&유실을 방지하기 위해 사용.
exception이 발생하면 마지막에 처리하던것을 commitSync()하고 consumer.close()를 이용하여 안전하게 종료하게 된다.
이를통해 리밸런스가 발생하는것을 브로커에 명시적으로 알려줄 수 있다.
Runtime.getRuntime().addShutdownHook(new Thread() { // <- shutdown 신호를 받으면 이 문장이 실행됨.
public void run() {
consumer.wakeup();
}
});
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
consumer.commitSync();
}
} catch (WakeupException e) { // wakeup()이 실행되면 poll()이 진행될때 exception발생
System.out.println("poll() method trigger WakeupException");
}finally {
consumer.commitSync(); // <- 커밋하고 종료될수있도록 지정
consumer.close();
}
단, wakeup메소드를 통해서 안전하게 종료되어야 의미가 있음. kill -9은 프로세스 강제종료로 커밋불가
컨슈머 - 쓰레드 전략
- 1프로세스 - 1스레드(컨슈머)
- 간략한 코드
- 프로세스 단위 실행/종료
- 다수의 컨슈머 실행 필요시 다수의 프로세스 실행 필요
$ cat consumer.conf
{"topic":"click_log", "group.id":"hadoop-consumers"}
$ java -jar one-process-one-consumer.jar --path consumer.conf
- 1프로세스 - n스레드(동일 컨슈머 그룹)
- 복잡한 코드
- 스레드 단위 실행/종료
- 스레드간 간섭 주의
- 다수 컨슈머 실행시 다수 스레드 실행가능
$ cat consumer.conf
{"topic":"click_log", "group.id":"hadoop-consumers", "consumer.no":20}
$ java -jar one-process-multiple-consumer.jar --path consumer.conf
- 1프로세스 - n스레드(다수 컨슈머 그룹)
- 복잡한 코드
- 컨슈머 그룹별 스레드 개수 조절 주의
$ cat consumer.conf
[
{"topic":"click_log", "group.id":"hadoop-consumers", "consumer.no":20},
{"topic":"click_log", "group.id":"elasticsearch-consumers", "consumer.no":1},
{"topic":"application_log", "group.id":"hadoop-consumers", "consumer.no":5}
]
$ java -jar one-process-multiple-consumer-multiple-group.jar --path consumer.conf
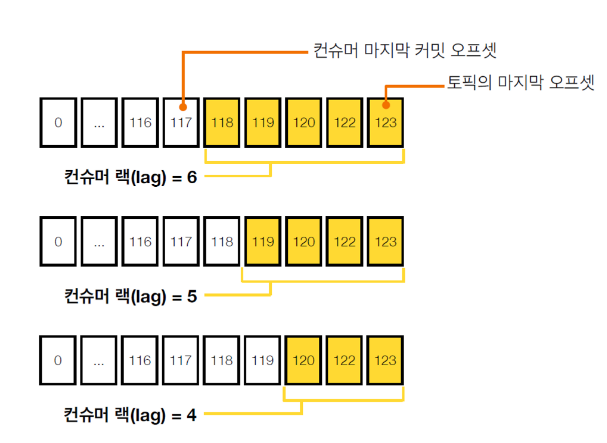
컨슈머 랙(Consumer lag)
컨슈머 랙은 컨슈머 상태를 나타내는 지표
컨슈머 랙의 최대값은 컨슈머 인스턴스를 통해 직접 확인가능
consumer.metrics()를 통해 확인할 수 있는 지표
- records-lag-max : 토픽의 파티션 중 최대 랙
- fetch-size-avg : 1번 폴링하여 가져올때 레코드 byte평균
- fetch-rate : 1초 동안 레코드 가져오는 횟수
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Map<MetricName, ? extends Metric> metrics = consumer.metrics();
for (MetricName metric : metrics.keySet()) {
System.out.println(metric.name() + " is " + metrics.get(metric).metricValue());
}
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
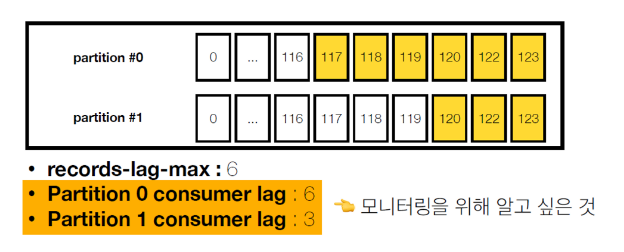
but, 위 방식처럼 컨슈머 인스턴스를 통한 컨슈머 랙을 수집하면 문제점이 발생한다.
- 컨슈머 인스턴스 장애가 발생하면 지표 수집 불가능
- 구현하는 컨슈머마다 지표를 수집하는 로직 개발필요
- 컨슈머 랙 최대값만 알수있음
- 토픽에 파티션은 n개가 있는데 최대값밖에 모름, 나머지는 모름
각각의 파티션의 랙을 알고싶을때는 카프카가 제공해주는방식으로만은 불가능하고, 컨슈머 랙 모니터링 (외부 모니터링) 애플리케이션을 사용해야함
- confluent platform, datadog, kafka burrow(오픈소스) 등을 사용
'IT > 오픈소스' 카테고리의 다른 글
| 프로메테우스(Prometheus) 오픈소스란? (0) | 2024.05.05 |
|---|---|
| JPA - 기본 개념 (1) | 2024.01.30 |
| 카프카(Kakfa) 개념정리 (1) | 2023.09.11 |
| Docker란? (1) | 2023.03.26 |
| 네티(Netty) 기본정리2 (0) | 2022.02.22 |




댓글