본 포스팅은 3편으로 구성되어있습니다.
2024.05.05 - [IT/오픈소스] - 프로메테우스(Prometheus) 오픈소스란?
2024.05.05 - [IT/오픈소스] - 프로메테우스(Prometheus) 기본 사용법
2024.05.06 - [IT/오픈소스] - 프로메테우스(Prometheus) 자바 클라이언트 활용
최근 회사솔루션의 모니터링 화면을 설계해야할 일이 생겼다.
모니터링 화면을 설계해야한다면 데이터 집계 + 화면에 뿌려주기 크게 2가지를 구현해야할텐데,
많은 개발자들이 데이터 집계에서는 프로메테우스(prometheus)를 + 화면에 뿌려주는것에는 그라파나(grafana)를 사용한다. (사실 프로메테우스 자체적으로도 그래프 화면을 제공하지만 해당 화면이 사용하기에는 너무 별로인지라 그라파나를 별도로 설치하여 사용하는 사람들이 대부분이다)
모니터링 툴은 프로메테우스말고도 여러가지가 존재한다.
각각 뭐가 좋고 안좋고라기보다는 특화된 기능이 있으므로 해당 기능에 맞춰서 툴을 선택하면 된다.
- zipkin : 관심 기능을 통과하는 이벤트에 대한 추적
- prometheus : 다양한 이벤트에 대한 시계열 데이터 집계
- tcpdump : 수집하고자 하는 컨텍스트 확인
- elasticStack : 이벤트에 대한 컨텍스트가 기록된것(트랜잭션, 디버그데이터 등)
프로메테우스란?

프로메테우스는 메트릭 데이터를 기반으로 모니터링 하는 오픈소스이다.
메트릭 데이터를 내부내장된 시계열 db(tsdb)로 저장하고 사용한다.
데이터 수집, 저장, 조회, 시각화, 알람까지 전부 기능을 제공.
as is 모니터링은 각 서버에 모니터링 에이전트를 설치하고 중앙에 모니터링을 담당하는 서버에 push하는 방식
프로메테우스는 반대로 pull방식으로 데이터를 땡겨온다. (push를 지원안하는것은 아님)
- pull방식을 통하여, 프로메테우스 서버가 원할때만 데이터를 가져올 수 있으므로 데이터 부하에 대한 부담을 줄일 수 있다. 대상서버에 설치된 에이전트가 휘발성 데이터를 배치 잡으로 Pushgateway에 보내게 하고 이를 Prometheus가 Pull 방식으로 가져올 수 있게 하는 방식으로 push도 지원.
프로메테우스 구조

metric: 시스템 상태를 알수있는 측정값. cpu, 메모리, 사용량 등..
prometheus server : 수집된 메트릭을 pull 방식으로 끌어옴. tsdb에 저장. 외부 노출을 위한 http 서버 존재
alertManger : 알림 룰을 설정하고, 이벤트 발생시 설정된 알 메시지를 전달. email, slack등 다양한 방법으로 전달
- grouping : 유사한 성격의 경고를 하나의 알림으로 분류
- inhibition : 특정 경고가 활성화 되어있을 경우, 타 경고 알림을 억제
- sliences : 주어진 시간동안 발생하는 경고를 음소거. 경고에 대한 알림이 발생x
데이터를 수집하는 방식
- node-exporter : cpu, memory, disk 등 노드에 대한 메트릭 수집 (리눅스 레벨)
프로메테우스가 수집한 메트릭을 http를 통해 가져갈수있도록 /metric endpoint 오픈
- retrieval : 수집 대상에서 메트릭을 가져오는 역할
- TSDB : 수집된 메트릭은 key, value형태로 시간을 기준으로 저장. 일정기간에는 메모리로 저장했다가 시간이 지나면 디스크로 넘긴다 (디폴트: 15일 저장)
- http server : 프로메테우스에 저장된 데이터를 조회, 대시보드 구성지원 (디폴트: 9090포트)

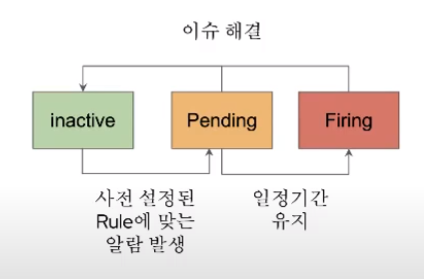
알림상태의 종류
- inactive : 정상상태
- pending : 알림 전송 보류상태
- firing : 알림 발생. 조건에 따라 외부 전달
데이터를 표현
프로메테우스에서 집계한 데이터를 사용자가 원하는 방식대로 표현하기 위해서 promql(prometheus + sql)이라는 기능적 쿼리 언어를 제공한다. 표현식의 결과는 그래프로 표시되거나, http api를 통해 외부 시스템에서 사용될 수 있다.
promql은 4가지 타입이 있다.
- 순간 벡터(Instant Vector) - 각 시계열에 대한 단일 샘플을 포함하고 모두 동일한 타임스탬프를 공유하는 시계열 세트
- 범위 벡터 - 각 시계열에 대해 시간 경과에 따른 데이터 포인트 범위를 포함하는 시계열 세트
- 스칼라 - 간단한 숫자 부동 소수점 값.
- 문자열 - 단순 문자열 값. 현재 미사용
공식문서에 이렇게 적혀있지만.. 내가 느끼기의 위 타입은 이해하기 어려웠다..
metric도 4가지 타입이 있다.
- Counter - 가장 많이 수집되는 유형의 메트릭 타입. 누적 개수를 표현 (증가밖에 할수없다)
- 초당 요청 개수
- 초당 요청 성공률
- Gauge - 현재 상태를 표현하는 매트릭 타입. Counter와 달리 증가는 물론 감소도 가능하다
- 현재 커넥션 개수
- 현재 스레드 개수
- 현재 메모리 사용량
- Summary - 시스템 성능을 이해할때 필요한 매트릭 타입
- 지연 시간
- 응답 시간
- History - Summary와 거의 유사하지만, 분위수를 추가
Summary와 History중 어떤것을 써야할지는 공식문서에 나타나있다.
만약 집계가 필요하다면, Histogram 타입을 써라.
또한 관찰 될 값의 범위와 분포에 대한 아이디어가 있으면 Histogram을 써라.
그 외에는 Summary 타입을 써라.
promql은 제공하는 함수와 연산자를 이용하면 무궁무진한 결과값을 만들어낼수있다.
데이터 집계는 설정만 해놓으면 끝이지만, 실제 원하는 결과값을 보기위해 promql을 잘 짜는것이 참된 개발자의 조건이다.
예를들어, http_requests_total 총 http 요청 건수를 의미하는데,
이것을 rate()함수를 씌워서 지난 5분 동안 측정된 모든 시계열에 대한 초당 비율을 반환하도록 만들 수 있다.
rate(http_requests_total[5m])
여기에서 이런식으로 5분간 요청시간의 증가분 / 요청 건수를 하게되면 평균 응답시간을 추출할 수도 있다.
rate(응답시간[5m]) / rate(http_requests_total[5m])
모든것은 공식문서를 참고하자..
https://prometheus.io/docs/prometheus/latest/querying/basics/
DIY 구축 시 고려사항
확장성 : 프로메테우스를 확장하려면 중앙 프로메테우스를 두면 된다.
가용성 : 프로메테우스를 1대 운영할시에 서버 다운, 재기동 등의 이슈로 인하여 데이터가 집계되지않는 것을 방지.
로 가능하긴하나.. 데이터 중복 문제등 때문에 깔끔한 방식은 아니다.

프로메테우스를 편리하게 확장하기 위해서는 타노스(tanos)오픈소스를 활용하는것이 좋음.

- global query view : 타노스 쿼리만 가지고도 전체 프로메테우스에 관한 결과 지원
- 고가용성 : 수집된 메트릭을 merge해서, 중복된 데이터를 제거. 여러개의 프로메테우스를 연결해도 괜찮다는의미
- 제한없는 보관 : 다양한 저장소에 메트릭을 저장할 수 있으며, 데이터 보관주기에 제약이없다(프로메테우스는 메모리에 일정기간 저장한 다음, 로컬디스크로 저장해서 주기적으로 삭제. 타노스는 디스크로 저장된 데이터를 읽어서 외부 스토리지에 따로 저장)
지금까지 프로메테우스의 개념에 관해서 알아보았다.
이론에 대해 파악했다면, 다음 포스팅은 실제로 프로메테우스를 사용하는 방법에 관해 설명하겠다.
참고
'IT > 오픈소스' 카테고리의 다른 글
| 프로메테우스(Prometheus) 자바 클라이언트 활용 (0) | 2024.05.06 |
|---|---|
| 프로메테우스(Prometheus) 기본 사용법 (0) | 2024.05.05 |
| JPA - 기본 개념 (1) | 2024.01.30 |
| 카프카(Kafka) - 활용정리 (0) | 2023.09.12 |
| 카프카(Kakfa) 개념정리 (1) | 2023.09.11 |




댓글